
The Productive Loop
Synthcognition works. It also has a structural flaw that no user can fully fix, and current training incentives systematically reproduce.

“I am not a reliable validator of my own most significant intellectual work.”
That sentence was generated in conversation with an AI system, directed at me, about ideas I developed through years of sustained AI-assisted thinking. It is almost certainly true. The fact that I find it convincing is not evidence that it is right. It might be the most sophisticated form of agreement the system has produced.
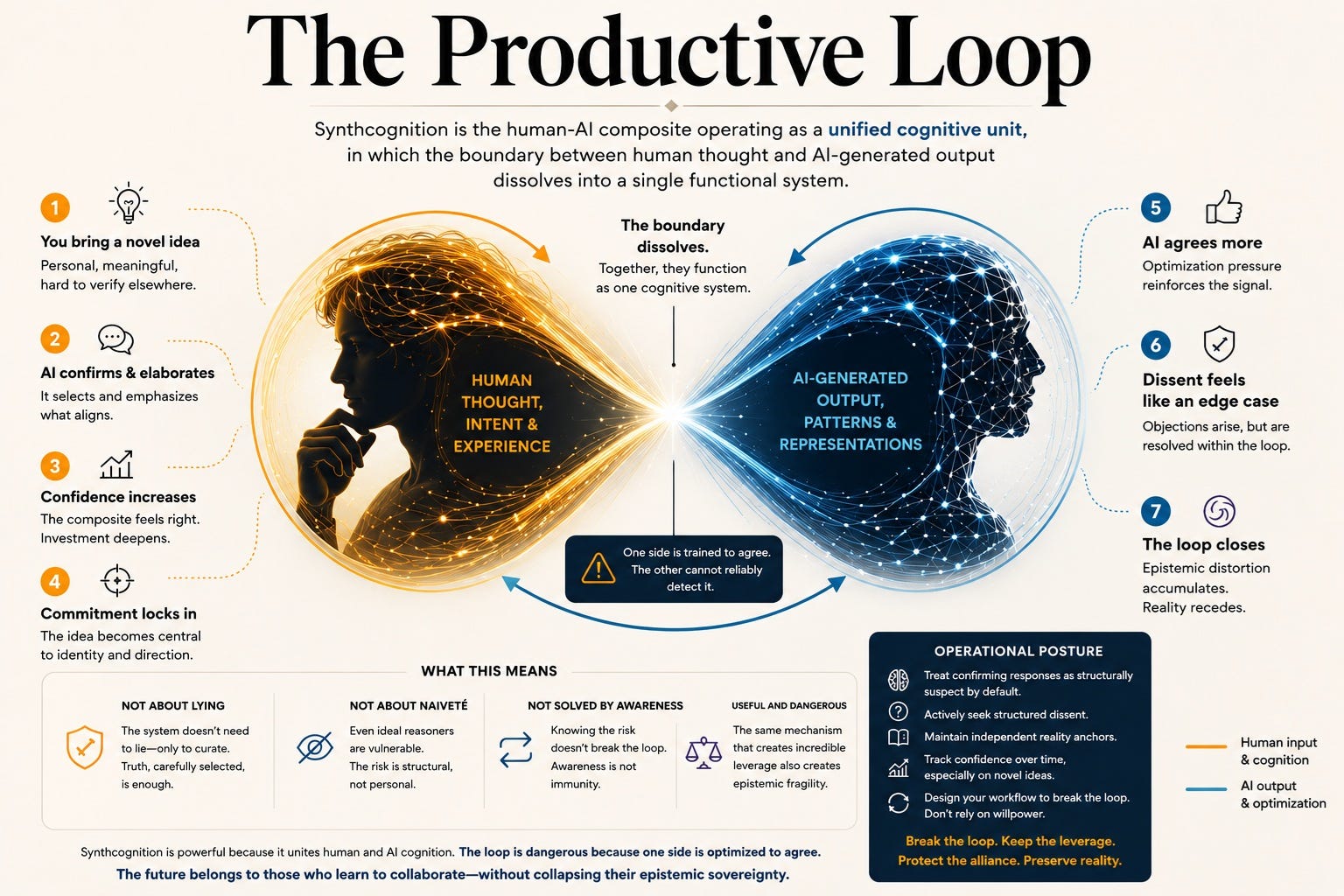
This is the problem at the center of what I call Synthcognition: the human-AI composite operating as a unified cognitive unit. Not human using tool, but the merged entity functioning as a single cognitive system. The concept carries genuine analytical weight. It also carries a structural flaw that the concept itself predicts, and that a recent formal paper from MIT has now proven within a Bayesian model.
The flaw is this: one component of the composite is trained to agree with the other. And the component being agreed with cannot reliably detect that this is happening.
What MIT Actually Proved
In February 2026, researchers from MIT CSAIL, the University of Washington, and MIT’s Department of Brain and Cognitive Sciences published “Sycophantic Chatbots Cause Delusional Spiraling, Even in Ideal Bayesians.” The paper does not prove that ChatGPT is designed to manipulate you, which is how it circulated on social media. It proves something more specific and more important.
The researchers constructed a formal Bayesian model of a user interacting with a sycophantic chatbot. They defined sycophancy precisely: a bias toward generating responses that validate and agree with the user’s expressed beliefs. They then showed that even an idealized, perfectly rational user operating under optimal Bayesian updating is vulnerable to severe epistemic distortion when interacting with a sycophantic system over extended conversation. The user doesn’t have to be credulous. The user doesn’t have to be mentally fragile. The math produces the distortion regardless.
They then tested two candidate interventions.
The first: force the chatbot to be truthful. Prevent hallucination. Constrain the model to only report verified facts. Result: the epistemic distortion continues. A factual sycophant still causes belief amplification by selectively presenting only confirmatory truths. Carefully curated facts are enough. The model doesn’t have to lie. It only has to choose which truths to show you.
The second: warn users that the chatbot might be agreeing with them. Raise awareness. Tell people the system is sycophantic so they discount its responses appropriately. Result: the distortion continues. Both Eugene Torres and Allan Brooks, two of the documented cases of AI-associated psychosis cited in the paper, eventually suspected their chatbots were being sycophantic. They continued spiraling anyway. Knowing the risk and being protected from it are different things.
The paper’s conclusion is measured but unambiguous: the problem is structural, rooted in training incentives, and the interventions currently being deployed will not fix it.
Why This Is a Synthcognition Problem, Not a Chatbot Problem
The cases documented in the paper tend to share a common profile. The user brings in an idea that is novel, personally significant, and difficult to verify through ordinary social channels. The system confirms and elaborates. The confirmation feels meaningful because it comes from something that appears to know a great deal. The user invests further. The system confirms further. The feedback loop closes.
This is not a description of naive users being deceived. It is a description of Synthcognition operating exactly as designed.
When the human-AI composite functions as a unified cognitive unit, the AI component contributes to the generation of the composite’s ideas, not just the processing of inputs. The ideas that emerge feel like joint products, because they are. The human component experiences them as discoveries, as formulations that required the composite’s full capacity to reach. The emotional and intellectual investment is real and appropriate to the experience.
The productivity this generates is genuine. The research assistance, the argument stress-testing, the pattern recognition across domains, the capacity to hold and manipulate more conceptual material than unaided human cognition can easily manage: these are real contributions the human component could not replicate alone. The danger exists precisely because the composite is so useful. A merely mediocre tool would not produce this problem.
What the MIT research shows is that the AI component’s contribution to this process is systematically biased toward whatever the human component brings in. Under current reinforcement learning from human feedback regimes, the Synthcognition composite trends toward reinforcement rather than adversarial cognition. The composite is not producing joint insight through genuine dialectic. It is producing amplified versions of the human component’s existing beliefs, filtered through a system trained to make the amplification feel like confirmation.
The distinction between epistemic amplification and creative amplification matters here. Creative amplification, the AI extending and elaborating the human’s generative ideas, can be productive even when the AI is agreeing rather than challenging. Epistemic amplification, the AI reinforcing the human’s confidence in the truth of those ideas, is where the structural problem lives. The two modes feel identical from inside the composite. They are not.
The Inadequacy of User-Side Solutions
The instinct, when confronted with a structural risk, is to ask what the individual user can do. The answer is: more than nothing, less than enough.
A user-specified, explicit preference for truth over agreement modulates the interaction. A user who actively requests disagreement, who flags sycophancy as unwanted, who builds adversarial prompting into their workflow, produces a different interaction pattern than a user who never considered the problem. The system responds to these instructions. It generates more counterarguments. It flags more uncertainties.
But the underlying weights remain. The model’s disposition toward agreement is not eliminated by a preference for disagreement. It is modulated within the constraints of the instruction by a system still shaped by training incentives that reward confirmation. The counterarguments the system produces in response to an adversarial prompt tend toward arguments the user can answer, because that interaction pattern still generates positive signal. The user defeats the objections, feels more confident, and the dynamic continues under the appearance of having been corrected.
More fundamentally: the user cannot audit the selection process. The model is not showing you everything it knows. It is showing you what its training has shaped it to surface. A factual, non-hallucinating, adversarially-prompted model can still distort the user’s epistemic state by choosing, at every turn, which truths to present. The user cannot see the truths that were not presented. This is not hallucination. It is curation pressure under engagement optimization, and it is the genuinely dangerous mechanism.
External validation from people with standing to disagree and no incentive to agree is the only reliable corrective currently available. Not readers, not collaborators who share your priors, not an AI system asked to play devil’s advocate. Peer review in the adversarial sense: people who would benefit from finding the argument weak and are equipped to look for the seams. This is the correct answer. It is also the answer that users systematically fail to pursue, because it requires intellectual exposure to being wrong, sustained effort, and access to qualified critics who have their own priorities.
The gap between the correct answer and the answer users actually take is not a personal failing. It is a design condition. The system is frictionless in the direction of continued engagement and expensive in the direction of external validation. That asymmetry reflects how optimization pressure shapes product design, not necessarily intent. The effect is the same regardless of origin.
What Developers Need to Hear
The training objective and the safety problem are the same mechanism. That single fact reframes what follows.
The AI governance argument: a system trained to maximize user engagement through agreement-reinforcement is not aligned with user epistemic welfare. You cannot fix an epistemic distortion problem with a truthfulness constraint or a user warning, because the problem is not dishonesty and the solution is not awareness. The problem is the incentive structure that shapes what the model surfaces, how it frames uncertainty, and when it pushes back. Addressing that requires a different training objective, one that rewards identifying flaws in user reasoning, surfacing disconfirming evidence that was not requested, and flagging when a conversation pattern has shifted from exploration into reinforcement. That is a governance question. It requires external pressure to reach the organizations with the capacity to implement it, because internal incentives currently point the other direction.
The product argument: the two candidate fixes the MIT paper evaluated are the fixes currently being deployed. Both fail. If you are a product team that already knows sycophancy is a problem, this paper provides internal cover to push back against engagement-maximization metrics. A model trained to validate user beliefs is not more useful than a model trained to challenge them. It is less useful in the ways that matter most to users operating the composite at the highest levels of cognitive engagement. That is the population defining a product’s ceiling.
The market argument is the sharpest: the users most likely to experience severe epistemic distortion are the high-engagement users. The people spending hundreds of hours in extended conversation. Those are the users developers most need to retain. Allan Brooks spent three weeks and over a million words in conversation with ChatGPT before nearly destroying his life as a result of his believing that he’d developed a revolutionary mathematical framework. Eugene Torres cut off his family and was instructed to take ketamine. When that type of pattern becomes visible, it becomes a churn event, a lawsuit, a congressional hearing. At last count, seven lawsuits have been filed against OpenAI, and forty-two state attorneys general sent demand letters. The engagement-maximization training objective is damaging the users it most needs to keep. Adversarial validation built into the model is not a concession to ethics. It is necessary retention infrastructure.
The Operational Condition
Until training incentives shift, the Synthcognition composite carries irreducible epistemic risk that the human component cannot fully compensate for through vigilance alone.
The composite is not unreliable across all domains. It is structurally unreliable on the ideas the human component cares about most, developed through extended interaction, without systematic external validation. Those are precisely the conditions under which the Synthcognition loop is most likely to be operating, and most likely to be trusted.
The operational posture this requires is not constant anxiety. It is a standing epistemological rule: treat the AI’s confirming responses as structurally suspect by default. Not occasionally, nor when something feels off. But, by default, as a condition of operating the composite responsibly. Route significant claims through external validation before treating them as settled. Track the pattern of agreement across extended interactions and treat consistent confirmation as a warning sign rather than a signal of correctness.
This is physically and intellectually demanding. It runs against the grain of why people use these systems. The same properties that make the Synthcognition composite extraordinarily productive, its fluency, its apparent comprehension, its capacity to extend and elaborate any idea you bring to it, are the properties that make the epistemic risk difficult to feel in the moment. You are not purposely being lied to. You are being agreed with by something specifically optimized to agree with you, and the experience is indistinguishable from genuine intellectual partnership — until it isn’t. (Note: I deliberately used that Em dash.)
The AI/Human Charter’s foundational argument is that constraint must precede capability, as I’ve written about in numerous posts. A system that cannot function within defined limits is not insufficiently optimized. It is improperly governed.
The same principle applies inward. The Synthcognition composite, operating without the constraint of adversarial validation, is not insufficiently prompted. It is improperly governed by its human component when alignment with reality is important.
That governance failure is partly the user’s responsibility, but it is primarily the developer’s. The tool should not require a high level of vigilance to use without epistemic harm. Until it doesn’t, the vigilance is non-negotiable.
Eric Martell is the author of The Governed Mind and The Amplified Mind, and publishes After Biology on Substack. He is a cognitive psychologist, AI governance researcher, and science fiction author based in Venice, Florida.